
With the recent progress in generative AI, we are entering an era with endless creativities and possibilities. The success of stable diffusion and dreambooth made this possible to enable high-quality and diverse image synthesis from a given text prompt.
What if you want to personalize the text-to-image model to mimic the appearance of a specific person, object, or concept? DreamBooth, Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation is here to help.
How we built this?
A couple of steps to create your "personalized" text-to-image models.
- Prepare your input dataset
- Fine-tune the diffusion model with input images and class identifier
- Get inspiration for prompt in Artsio search and discover page
- Use the fine-tuned model for the subject driven image to text generation
Prepare dataset
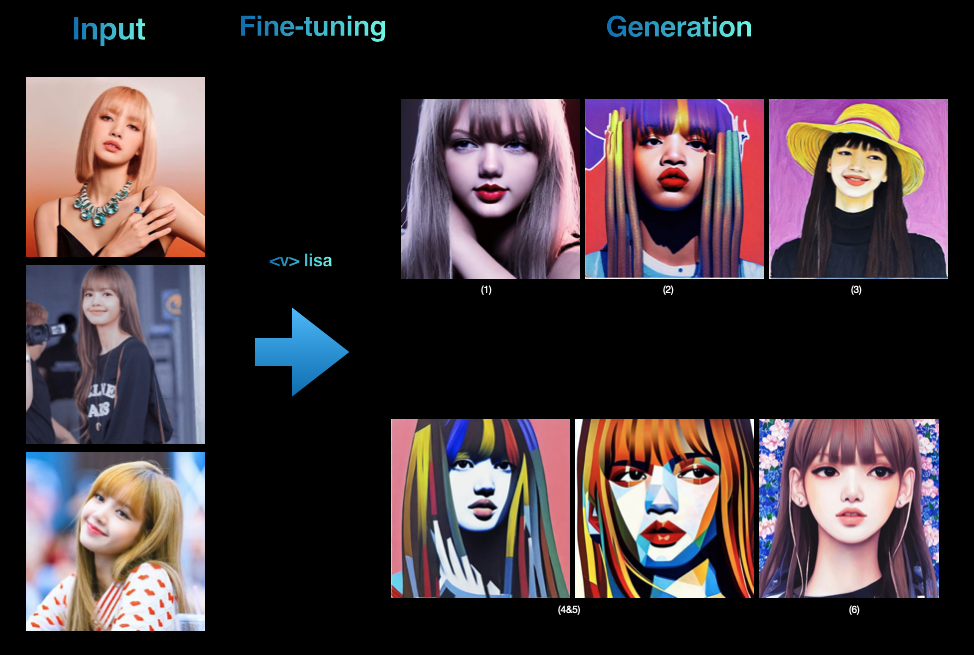
We downloaded 12 images of Lisa from google, with different backgrounds, facial expressions, angles of view, and lighting to bring some diversity, but still keep the collected images focused on portrait or upper body since we are doing portrait generation with the fine-tuned model in this example. Then these images are cropped and resized to 512x512 size.
Fine tuning the model
To fine-tune the model, we provided the following input:
- prepared 12 images of Lisa in the above step
- text prompts containing a unique identifier, in this case "
" - a class name of the subject, for example, "Lisa"
Subject driven image generation
Once we have the fine-tuned model for Lisa. We can load it with the stable diffusion pipeline to generate subject-driven images. But this is back to the challenging part of the image generation task, which is prompt engineering.
Luckily, we have millions of images for inspiration and prompt building. By typing a couple of keywords in the search box, we were able to get hundreds of images with a similar concept for discovery and inspiration, including their detailed prompt, and other parameters which are used for the generation.
With the curated prompt, we can generate deeply personalized images with stable diffusion while maintaining the attributes of the specific character, in this case "
The following shows a couple of prompts and the structure used to generate the above images. During the fine-tuning stage, we bind the
1). "a photo of a
2). "a photo of a
3). "a photo of
4&5). "a photo of a
6). "an ultra-detailed beautiful painting of a stylish
Why this matters?
• Subject and context matters. With fined tuned diffusion model, we not only can achieve high-quality and creative image generation, but also maintain the rich visual features of specific subsets, to be rendered in a different context, and bring "personalization" into the generative world.
• Few shots. The fine-tuning process uses a few-shot paradigm, which only takes a couple of example images as input while capturing and preserving the subject features substantially.
• Broader domains. In this example, we use the portrait as a use case to demonstrate the power of fine-tuning. But this approach applies to other domains and subjects, like specific scenes, objects, or even the concept to be fined tuned and deployed for personalized image generation.
Learn more
If you are interested to learn more about the workflow and would like to build your personalized image generation model, feel free to contact us at info@artsio.xyz